{kind=link}
RNA and protein synthesis
Use this simulation to explore RNA and protein synthesis!
The central dogma of molecular biology describes the flow of genetic material within a biological system. This process is fundamental to understanding how proteins are made using genetic instructions in DNA. Understanding protein synthesis is key to developing therapies in medicine, enhancing crop yields in agriculture and creating new biotechnologies.
The synthesis of proteins is explained using the central dogma (“central dogma” just means it is a fundamental principle or concept). It tells us that DNA is copied into messenger RNA (mRNA) through a process called transcription and then mRNA is used to make proteins in a process called translation.
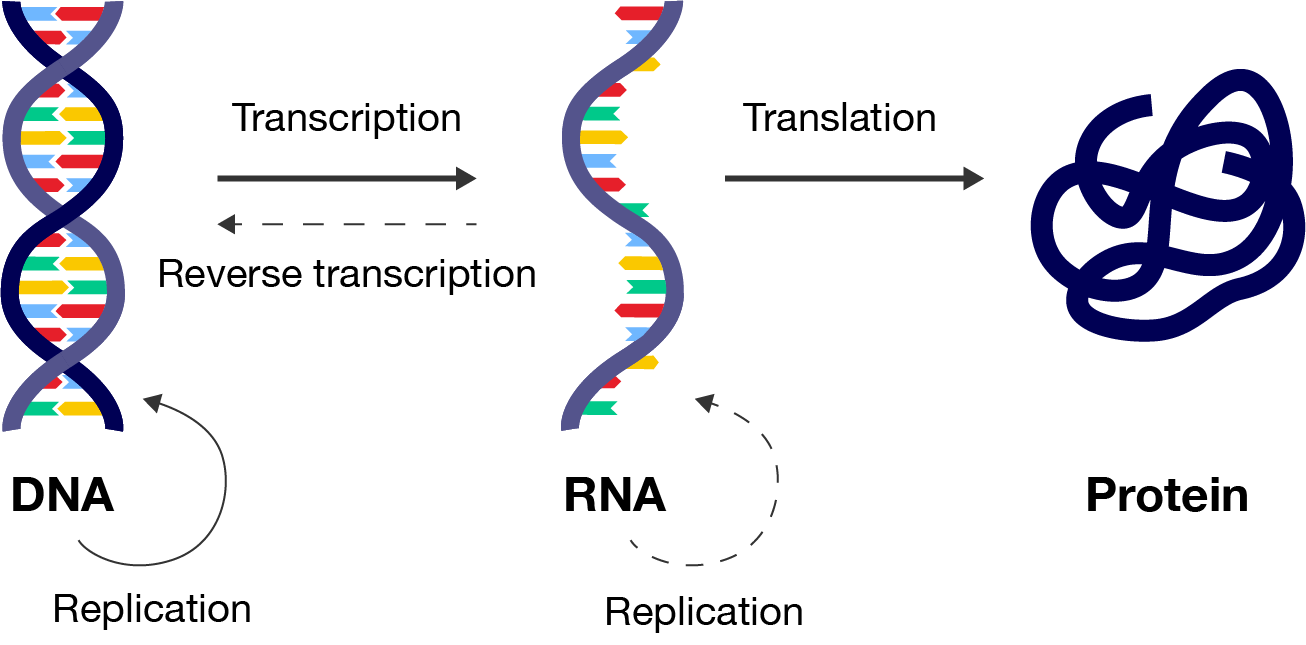
A three-step flowchart, starting with "DNA" on the left, "RNA" in the middle and "Protein" on the right. DNA is represented by a double-helix. RNA is represented with a single strand of DNA. Protein is represented by a thick coiled line.
You will soon learn that this process is very complex, with a number of modifications that occur to the mRNA and protein before it is ready for use by the body. Any errors with these processes could lead to a malfunctioning protein.
Transcription (“trans” means “across” and “scribe” means “write”) is the process in which a specific segment of DNA is copied into mRNA. This mRNA strand contains the genetic blueprints for making a protein.
There are three steps to transcribing DNA, which occur in the nucleus of eukaryotic cells: initiation, elongation and termination.

A diagram showing the initiation of transcription. A segment of double-stranded DNA is shown, with part of it on the far left labelled "Promoter region". At the promoter region, a purple blob is attached. It is labelled "RNA polymerase".
This diagram shows the binding of the RNA polymerase enzyme to the promoter region of the DNA.
U and T are similar in structure. The presence of U instead of T indicates that the molecule is RNA, not DNA. Thymine helps keep DNA stable, while uracil is more useful in RNA as it requires less energy to produce.
A diagram showing the elongation stage of transcription. A segment of double-stranded DNA is shown. The RNA polymerase has attached to the bottom strand and moved along it, as shown by an arrow. From the promoter region on the far left and extending to the right up until where the RNA polymerase is, the strands of DNA have separated from each other, or unwound. Coming out from the RNA polymerase is a new strand of nucleotides labelled "mRNA". The nucleotide squence matches the top strand and is complementary to the strand that the polymerase has moved along and read.
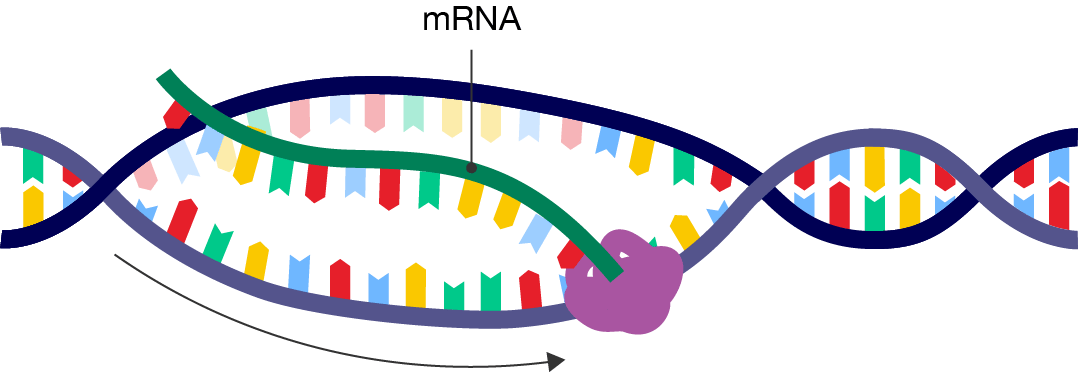
Elongation step of transcription
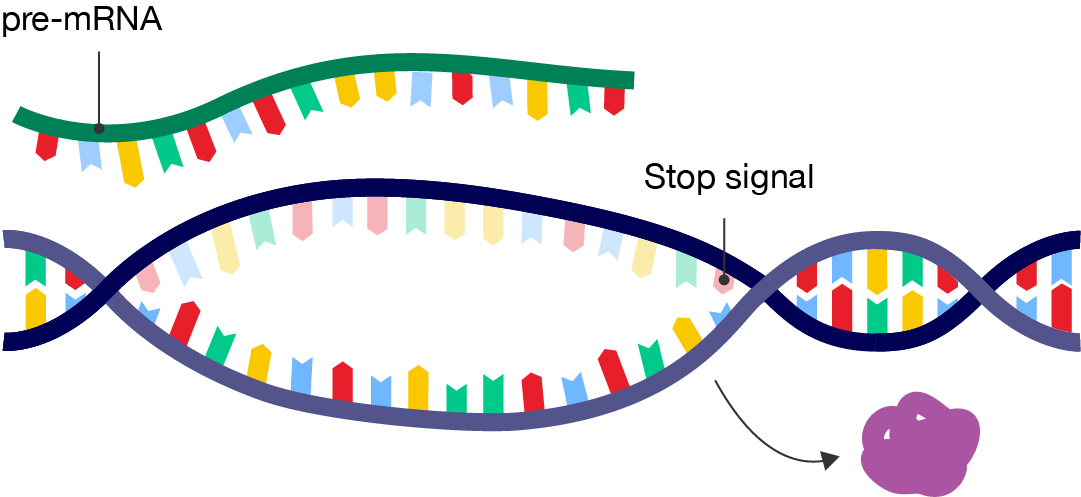
A diagram showing the termination of transcription. A segment of double-stranded DNA is shown, with a "Stop signal" labelled on the far right. Between the promoter region and stop signal, the DNA double helix has unwound.
The purple RNA polymerase enzyme has detached from the DNA, shown by an arrow.
Above the double-stranded DNA is a singe strand labelled "pre-mRNA". Its sequence matches the top strand in the DNA.
Watch this video to see transcription in action.
What you are about to see is DNA's most extraordinary secret — how a simple code is turned into flesh and blood. It begins with a bundle of factors assembling at the start of a gene. A gene is simply a length of DNA instructions stretching away to the left. The assembled factors trigger the first phase of the process, reading off the information that will be needed to make the protein. Everything is ready to roll: three, two, one, GO! The blue molecule racing along the DNA is reading the gene. It's unzipping the double helix, and copying one of the two strands. The yellow chain snaking out of the top is a copy of the genetic message and it's made of a close chemical cousin of DNA called RNA. The building blocks to make the RNA enter through an intake hole. They are matched to the DNA - letter by letter - to copy the As, Cs, Ts and Gs of the gene. The only difference is that in the RNA copy, the letter T is replaced with a closely related building block known as "U". You are watching this process - called transcription - in real time. It's happening right now in almost every cell in your body.
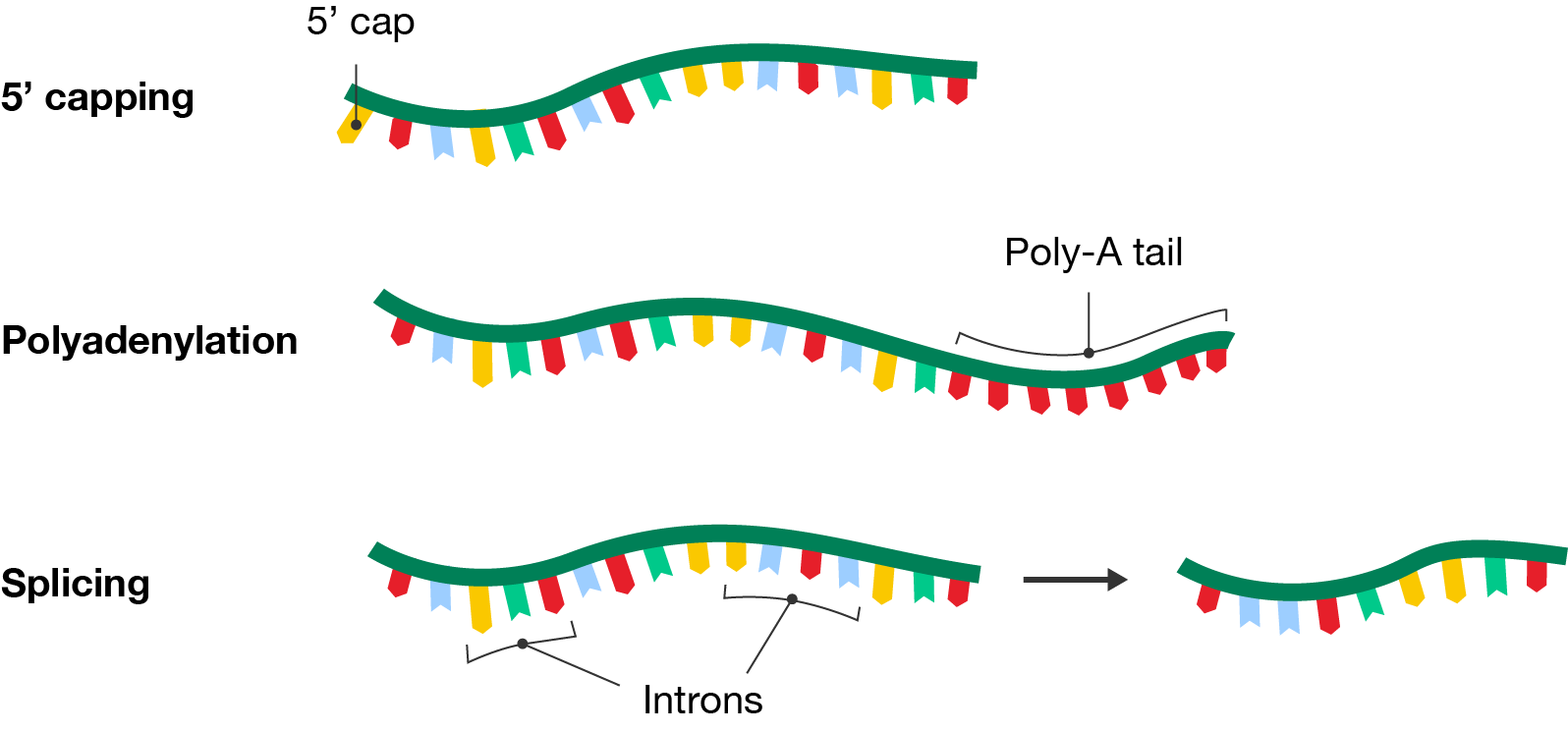
In eukaryotes, transcription forms pre-mRNA which needs to undergo additional modifications like 5’ capping, polyadenylation and splicing to prepare it for translation.
Translation is the conversion of the genetic code from the mRNA into a specific sequence of amino acids, forming a polypeptide or protein. It occurs within ribosomes, which consist of two subunits. The small subunit binds the mRNA transcript and the large subunit binds transfer RNA (tRNA).
Ribosome by MajoraMaster on Sketchfab, licensed under CC BY 4.0
tRNA molecules read the mRNA template in sets of three nucleotides, called codons, with each codon corresponding to a specific amino acid. They bring the appropriate amino acids to the ribosome so they can be added to the polypeptide chain.
The codon chart is shown.
It organises the codons by the three bases that make them up: Each cell within the chart represents a codon made up of a combination of bases, specifying a particular amino acid or a start/stop signal. Here's a breakdown:
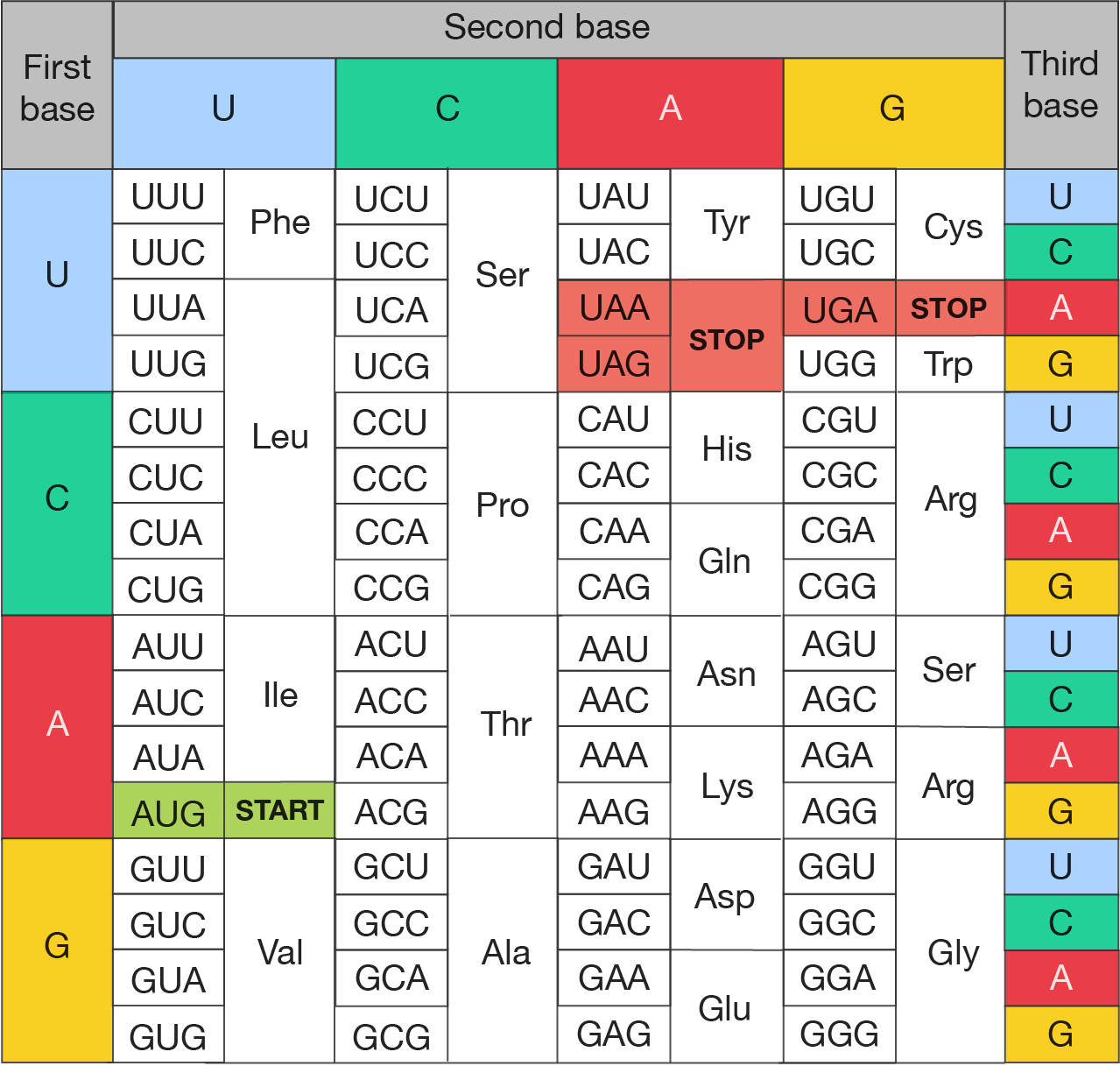 The image is a codon chart, used to identify amino acids coded by mRNA sequences during translation.
The image is a codon chart, used to identify amino acids coded by mRNA sequences during translation.
Codon chart
Like transcription, translation involves an initiation, elongation and termination step.
Once the start codon is identified and the small subunit, initiator tRNA and mRNA complex is formed, the next step can occur.
A diagram showing a segment of mRNA with a ribosome and transfer RNA attached. The small subunit of the ribosome is attached to the mRNA at the start codon. The large subunit is attached to an initiator tRNA molecule, which has methionine associated with it. The large subunit has three sites for tRNA to bind. The middle site is occupied by the initiator tRNA.
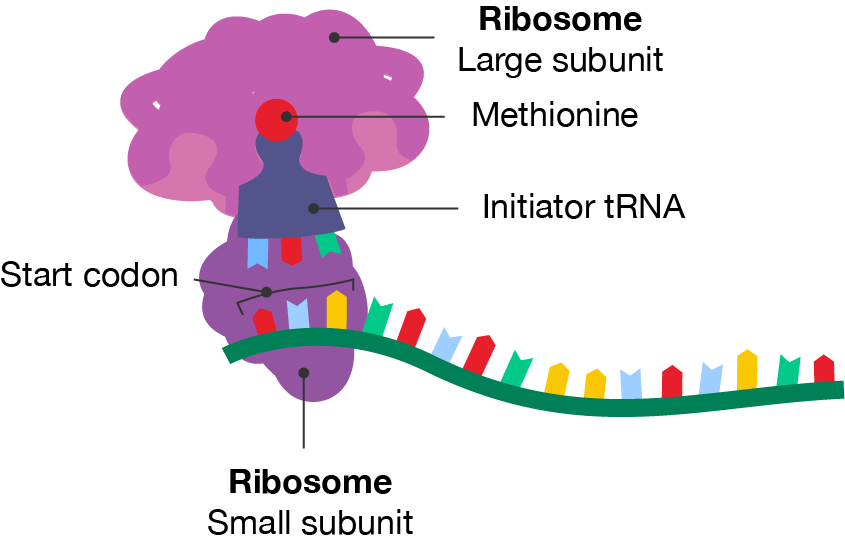
Initiation step of protein translation
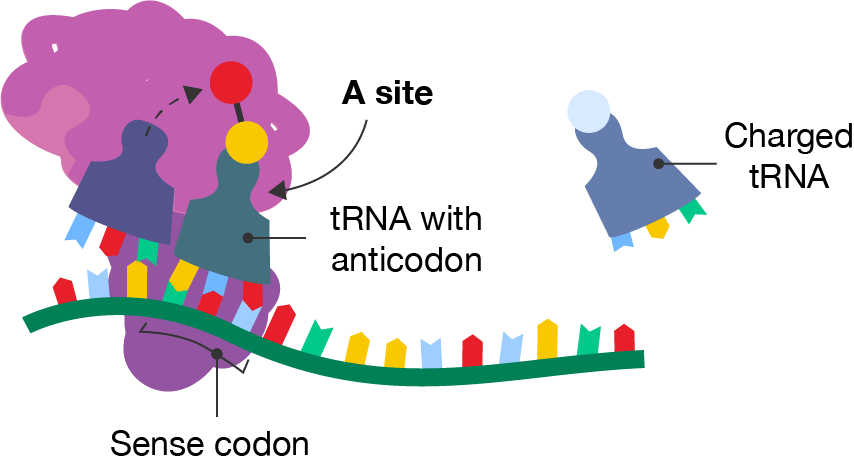
A diagram showing a segment of mRNA with a ribosome and two tRNA molecules occupying the middle and right-hand sites. The methionine is shown attaching to the amino acid on the tRNA in the right-hand site, which is labelled "tRNA with anticodon". The anticodon matches with the codon, labelled "Sense codon", on the mRNA strand. The right-hand site is labelled the "A site". Freely floating to the right is another tRNA molecule with a different amino acid, labelled the "Charged tRNA".
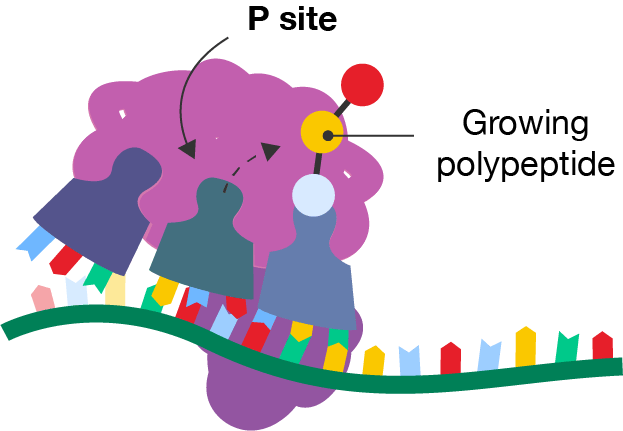
A diagram showing a segment of mRNA with a ribosome and three tRNA molecules occupying the left-hand, middle and right-hand sites. The amino acid is shown attaching to the growing polypeptide chain on the tRNA in the right-hand site. Each tRNA has moved one site to the left from the previous diagram. The middle site is labelled the "P site".
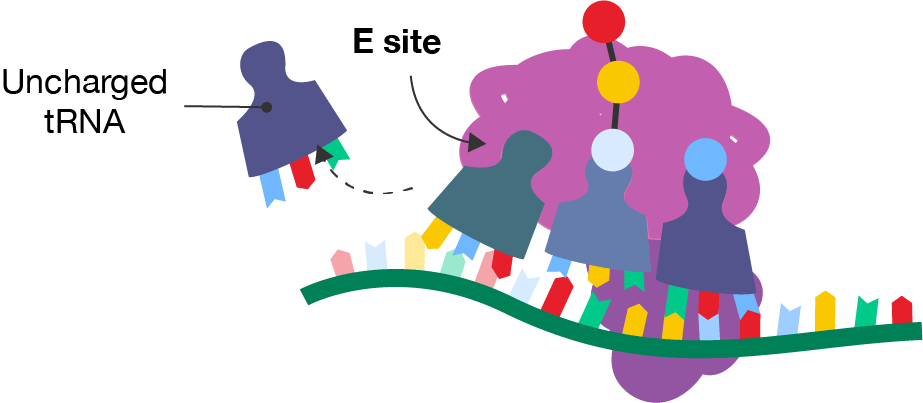
A diagram showing a segment of mRNA with a ribosome and three tRNA molecules occupying the left-hand, middle and right-hand sites. The right-hand site contains a tRNA molecule with a blue amino acid. The middle site contains a tRNA molecule with the rest of the polypeptide chain. The left-hand site is labelled the E site. Each tRNA has moved one site to the left from the previous diagram. Freely floating to the left is the tRNA molecule that was in the E site in the previous diagram. It is labelled the "Uncharged tRNA".
By freeing up the A site, the elongation process is made more efficient as the next tRNA molecule can add its amino acid.
When a nonsense codon reaches the A site, peptidyl transferase adds a water molecule to the carboxyl end of the amino acid. The protein is released from the ribosome and translation is complete. After this stage, the protein has acquired its primary structure.
A diagram showing the termination of translation. The right-hand site contains a tRNA molecule with no amino acid. It binds to a segment of the mRNA called the "Stop codon". The middle site contains a tRNA molecule with the final polypeptide chain. Each tRNA has moved one site to the left from the previous diagram.
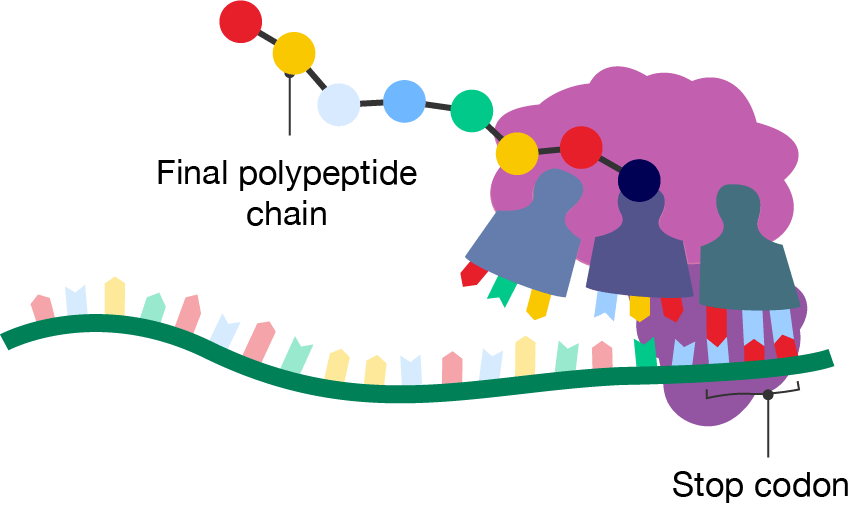
Termination step of translation
Watch this video to see translation in action.
When the RNA copy is complete, it snakes out into the outer part of the cell. Then in a dazzling display of choreography, all the components of a molecular machine lock together around the RNA to form a miniature factory called a ribosome. It translates the genetic information in the RNA into a string of amino acids that will become a protein. Special transfer molecules, the green triangles, bring each amino acid to the ribosome. The amino acids are the small red tips attached to the transfer molecules. There are different transfer molecules for each of the twenty amino acids. Each transfer molecule carries a three letter code that is matched with the RNA in the machine. Now we come to the heart of the process. Inside the ribosome, the RNA is pulled through like a tape. The code for each amino acid is read off, three letters at a time, and matched to three corresponding letters on the transfer molecules. When the right transfer molecule plugs in, the amino acid it carries is added to the growing protein chain. Again, you are watching this in real time. And after a few seconds the assembled protein starts to emerge from the ribosome. Ribosomes can make any kind of protein. It just depends what genetic message you feed in on the RNA. In this case, the end product is hemoglobin. The cells in our bone marrow churn out a hundred trillion molecules of it per second! And as a result, our muscles, brain and all the vital organs in our body receive the oxygen they need.
Just like after transcription, there are modifications that are often made after translation. This depends on the specific role of the protein, its destination within or outside the cell, and the needs of the cell.
There are many modifications that can be made to alter the protein’s function, activity, stability or location. Common examples are:
These modifications occur in the Golgi apparatus and endoplasmic reticulum. Then, the protein is folded into its secondary, tertiary and sometimes, quarternary structure.
Humans have over 100,000 different proteins. Together with the unique sequence of amino acids, post-translational modifications give proteins their specificity. This accounts for the diversity of proteins in the body.
See how well you understand how proteins are synthesised with a quick quiz.
Read the scenario and use the information provided to answer the questions in the quiz.
Dr Jean Nome wishes to investigate how differences in transcription affects the final protein production in cells.
She looks at five different genes and measures mRNA abundance (the number of copies of messenger RNA in each cell) and protein yield (the mass of protein in milligrams produced by each cell). Dr Nome measures the protein yield using colorimetry.
The results are presented in the following table.
| Gene ID | mRNA abundance (copies per cell) | Protein yield (mg per cell) |
|---|---|---|
| Gene A | \(500\) | \(50\) |
| Gene B | \(300\) | \(15\) |
| Gene C | \(700\) | \(25\) |
| Gene D | \(200\) | \(40\) |
| Gene E | \(600\) | \(30\) |
Images on this page by RMIT, licensed under CC BY-NC 4.0


RMIT University acknowledges the people of the Woi wurrung and Boon wurrung language groups of the eastern Kulin Nation on whose unceded lands we conduct the business of the University. RMIT University respectfully acknowledges their Ancestors and Elders, past and present. RMIT also acknowledges the Traditional Custodians and their Ancestors of the lands and waters across Australia where we conduct our business - Artwork 'Sentient' by Hollie Johnson, Gunaikurnai and Monero Ngarigo.
More information